
This paper describes how a model’s tendency to broadly integrate its parametric knowledge evolves throughout pretraining, and how this behavior affects overall performance, particularly in terms of knowledge acquisition and forgetting.
The concept of knowledge entropy is introduced, which quantifies the range of memory sources the model engages with; high knowledge entropy indicates that the model utilizes a wide range of memory sources, while low knowledge entropy suggests reliance on specific sources with greater certainty. Analysis reveals a consistent decline in knowledge entropy as pretraining advances.
The decline is closely associated with a reduction in the model’s ability to acquire and retain knowledge, leading us to conclude that diminishing knowledge entropy (smaller number of active memory sources) impairs the model’s knowledge acquisition and retention capabilities.
Further support for this is found by demonstrating that increasing the activity of inactive memory sources enhances the model’s capacity for knowledge acquisition and retention
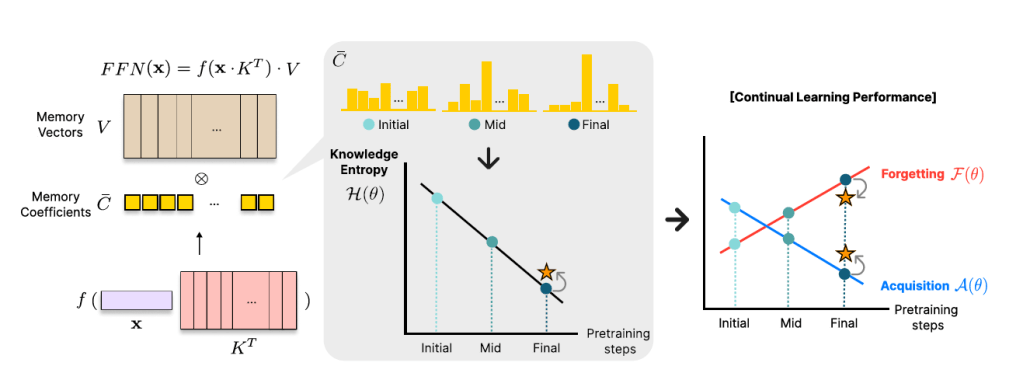
This sparsity deteriorates the model’s knowledge acquisition A(θ) and increases forgetting F(θ) when conducting continual knowledge learning with models from different pretraining stages.
Thereby, as denoted by the star, when we artificially increase the knowledge entropy of the final stage model, both knowledge acquisition and retention increase.
In this work, we examine how large language models’ ability to broadly integrate their parametric knowledge (measured by knowledge entropy) changes throughout pretraining and how these changes affect knowledge acquisition and forgetting in a continual learning setup. Our findings reveal a strong correlation between knowledge entropy and the model’s capacity to acquire and retain knowledge. Models in the final stages of pretraining tend to exhibit narrower integration of memory vectors, leading to lower knowledge entropy, which negatively impacts both knowledge acquisition and retention.
Interestingly, we could see that artificially increasing knowledge entropy by modifying the parameters of final-stage models tends to improve these capabilities. Based on our analysis, we suggest that models from the mid-stage of pretraining offer a good balance between knowledge acquisition, retention, and overall performance, making them a good choice for further training to introduce new knowledge.
