
“Complexity data science: A spin-off from digital twins “
Digital twins offer a new and exciting framework that has recently attracted significant interest in fields such as oncology, immunology, and cardiology.
The basic idea of a digital twin is to combine simulation and learning to create a virtual model of a physical object.
In this paper, we explore how the concept of digital twins can be generalized into a broader, overarching field. From a theoretical standpoint, this generalization is achieved by recognizing that the duality of a digital twin fundamentally connects complexity science with data science, leading to the emergence of complexity data science as a synthesis of the two. We examine the broader implications of this field, including its historical roots, challenges, and opportunities.
Complex systems have been studied for decades, but an essay by Warren Weaver from 1948 is often credited with outlining a vision for the field, which he summarized as the study of “organized complexity.” Complex systems denote particular systems or phenomena characterized by a multitude of interconnected elements or agents that interact, leading to the emergence of distinctive properties and behaviors. A prominent example is Boolean networks, which were introduced as a simplified model for gene regulation. However, many complex systems have been studied across multiple domains, including ecosystems, human behavior, and economic markets.
In recent years, complex systems have once again come into the center of interest, particularly as part of digital twin research.
The underlying idea behind a digital twin is often stated in simplified form as follows: a digital twin is an ideal concept a digital representation of a real-world object that closely mirrors its physical counterpart. This digital representation takes the form of a computer-based simulation model, while the real-world object can encompass systems or processes with a physical presence, such as an engine, biological cell, or economic process. The first applications of this concept can be found in manufacturing and engineering.
While digital twins originated in manufacturing, the concept has recently gained significant interest in various scientific fields, including health-related concerns, climate change mitigation, urban development, economic regulation, and sustainability. Although the benefits of digital twins in these newer fields are yet to be fully explored, the concept is generally met with high expectations.
From a theoretical perspective, a digital twin combines two key features that set it apart from other approaches: simulation and learning.
A consequence of the mechanistic nature of digital twins is that their models allow the exploration of “what-if” scenarios. This means that digital twins enable to examine the ramifications of virtual interventions performed on the structure of a model. Consequently, this offers the ability to gain insights into the effects of interventions.
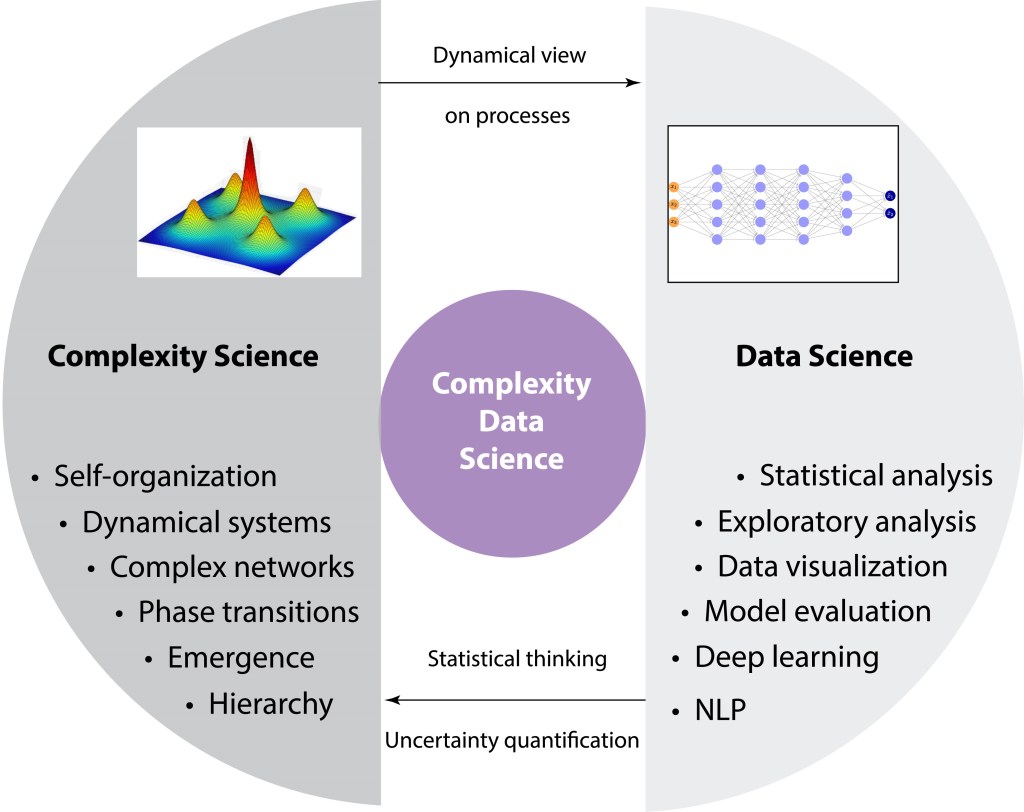
So far, we have focused on digital twins, by adopting a theoretical perspective, we can see that the complex systems underlying simulations are connected to complexity science, while learning is deeply rooted in data science.
Complexity science is a broad multidisciplinary field that explores complex phenomena in various domains, including physics, biology, sociology, economics, and more. Its primary focus is to unravel the fundamental principles, recurring patterns, and emergent behaviors inherent in complex systems. Complexity science strives to formulate overarching theories and frameworks that can be applied to a wide spectrum of complex systems, irrespective of their specific characteristics or domains. Since their inception, complexity science and the concept of complexity have defied a straightforward definition. Instead, they are better understood by identifying common themes, underlying threads, and the tools used in their study. It should be noted that this multidisciplinary field draws on a range of mathematical approaches, including stochastic processes, information theory, network theory, and statistical physics, illustrating the diverse and multifaceted nature of the discipline.
In contrast, data science is a field focused on extracting knowledge and insights from data using various techniques from statistics, machine learning, and AI. It involves the collection, processing, and analysis of large sets of data to identify patterns, make predictions, and inform decision making. Data science leverages machine learning algorithms, statistical models, and computational tools to handle complex data and derive actionable insights, focusing on practical applications and solutions to real-world problems across diverse areas.
The combination of simulation and learning inherent of digital twins has significant potential that extends beyond traditional digital twins. This integration could include specialized variations or extensions of digital twins that, while not strictly adhering to their foundational principles, still effectively merge simulation and learning. Fundamentally, the fusion of complexity science and data science can be termed “complexity data science,” representing the rise of a new field.

By calibrating a mechanistic or phenomenological model to a black-box prediction model, one can utilize such a model as surrogate for gaining interpretable insights into the underlying processes, while retaining the predictive power of the original black-box model.
In our increasingly complex world, we must constantly enhance our problem-solving tools to efficiently address emerging challenges. The present moment calls for expanding our capabilities through integrating complexity science and data science into a field we call complexity data science. This interdisciplinary approach holds the potential to provide novel insights and capabilities, pushing the boundaries of what can be achieved in domains that traditionally focus on either simulation or learning.
