
“Stable Diffusion Models Reveal a Persisting Human–AI Gap in Visual Creativity“
While recent research suggests Large Language Models match human creative performance in divergent thinking tasks, visual creativity remains underexplored.
This study compared image generation in human participants (Visual Artists and Non-Artists) and using an image-generation AI model (two prompting conditions with varying human input: high for Human-Inspired, low for Self-Guided).
The creativity of the resulting images was evaluated by human raters (N = 255) and GPT-4o acting as an AI rater under two conditions: strictly mirroring the human rating task and using in-context learning with human-rated examples as guidance.
We observed a clear creativity gradient: Visual Artists > Non-Artists ≥ Human-Inspired GenAI > Self-Guided GenAI.
Increased human guidance strongly improved GenAI’s creative output, bringing its productions close to those of Non-Artists. Moreover, while Guided-GPT-4o more closely approximated human creativity judgment patterns, baseline GPT-4o (without guidance) exhibited markedly different creativity evaluations, showing reduced discrimination between image categories and inflated scores for GenAI outputs.
These results suggest that, in contrast to language-centered tasks, GenAI models may face unique challenges in visual domains, where creativity depends on perceptual nuance and contextual sensitivity, distinctly human capacities that may not be readily transferable from language models.
… while GenAI can exhibit creative abilities when properly guided, it does not yet reach autonomous human-level performance.
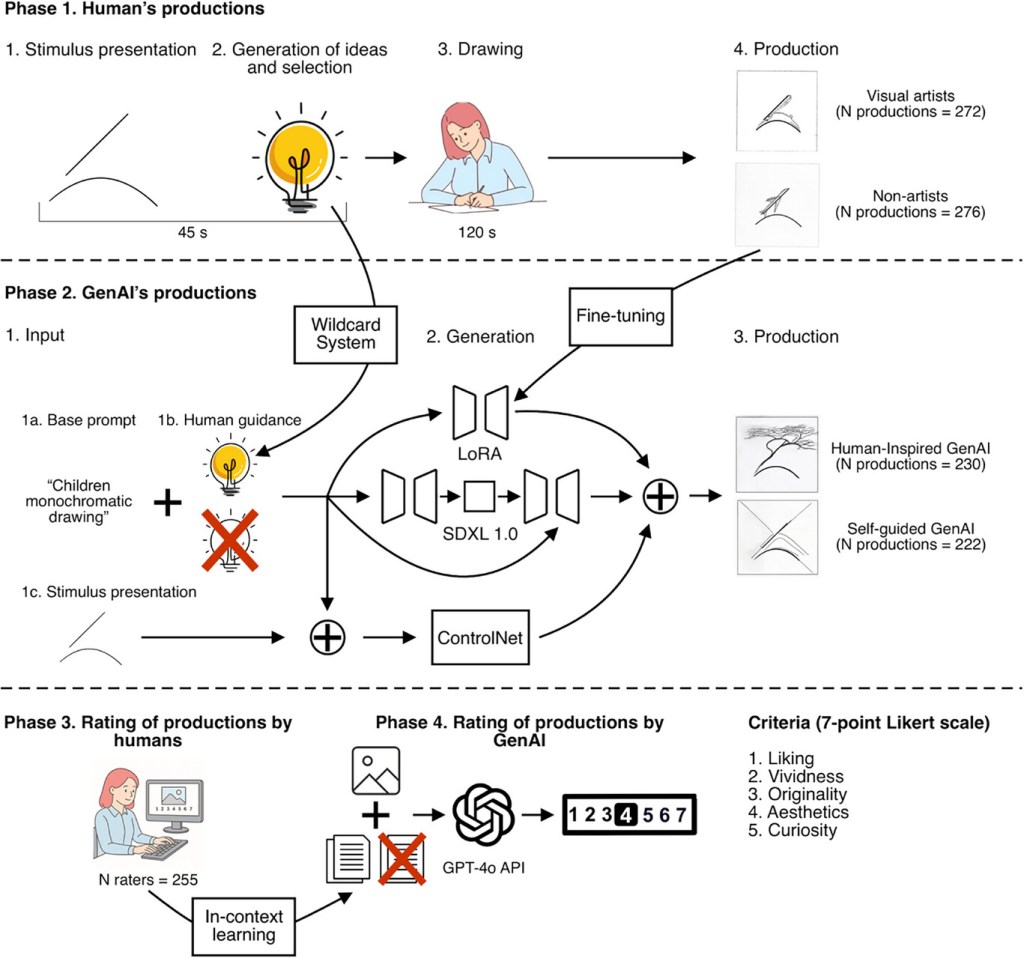
Phase I: Creative image generation by Visual-Artists and Non-Artists. The resulting human images were used to fine-tune the Diffusion model (SDXL) through Low-Rank Adaptation (LoRA), while the human-generated ideas were used in the prompt of the Human-Inspired GenAI group.
Phase II: Creative image generation by GenAI (Human-Inspired and Self-Guided).
Phase III: Creative image dataset rating by human raters.
Phase IV: Creative image dataset rating by both GPT-4o and Guided-GPT-4o (using in-context learning).
