
“Imagining and building wise machines: the centrality of AI metacognition”
- We examine the why and the how of building wise artificial intelligence.
- Wisdom helps humans navigate intractable problems through object-level strategies (for managing problems) and metacognitive strategies (for managing object-level strategies).
- Wise metacognition includes strategies such as intellectual humility, perspective-taking, and context adaptability.
- Wise artificial intelligence, through such improved metacognitive strategies, would be more robust to new environments, explainable to users, cooperative in pursuing shared goals, and safe in avoiding both prosaic and catastrophic failures.
- We suggest several approaches to benchmarking wisdom, training wise reasoning strategies, and adapting artificial intelligence architectures for metacognition.
Although artificial intelligence (AI) has become increasingly smart, its wisdom has not kept pace. In this opinion article, we examine what is known about human wisdom and sketch a vision of its AI counterpart. We introduce human wisdom as strategies for solving intractable problems—those outside the scope of analytic techniques—including both ‘object-level’ strategies, such as heuristics (for managing problems), and ‘metacognitive’ strategies, such as intellectual humility, perspective-taking, or context adaptability (for managing object-level task fit). We argue that AI systems particularly struggle with this type of metacognition. Wise metacognition would lead to AI that is more robust to novel environments, explainable to users, cooperative with others, and safer by risking fewer misaligned goals with human users. We discuss how wise AI might be benchmarked, trained, and implemented.
Where does artificial intelligence still struggle?
Despite recent breakthroughs, artificial intelligence systems (AIs) still face critical shortcomings. They struggle in novel, unpredictable environments, lacking robustness. Their computations are opaque, creating a problem of explainability. Their challenges with communication and credibility create barriers to cooperation. These shortcomings limit our ability to harness the benefits of artificial intelligence (AI) while avoiding risks and ensuring safety. As AIs increasingly act as agents in the world, these problems will be exacerbated.
But AIs are not the only intelligent agents that must solve these problems—we humans also face analogs of each of them. Might our own solutions yield some clues as to how AIs might do so more effectively?
We argue that one core set of capabilities underlies humans’ ability to make robust decisions, explain their reasoning, achieve goals cooperatively, and interact safely—wisdom. We examine the function and mechanisms of human wisdom, concluding that wisdom serves to solve intractable problems and proceeds via a suite of complementary object-level strategies (which provide possible solutions to problems) and perspectival metacognitive strategies (which are necessary to decide among the solutions). We then consider how humans use these mechanisms to solve our versions of the robustness, explainability, cooperation, and safety problems. By analogy, we suggest that fostering wisdom in AIs—particularly wise metacognition—will help address these problems.
What is wisdom?
Though philosophers have debated wisdom for millennia, empirically grounded models are recent.
The Berlin Wisdom Model defines wisdom as expertise in important and difficult life matters, combining knowledge (e.g., about human nature) with certain metacognitive strategies that are sensitive to context, value pluralism, and uncertainty.
The MORE Model highlights how wise people build psychological resources—such as managing uncertainty and developing open reflectiveness toward experiences and perspectives—to cope with life’s challenges.
Balance Theory emphasizes how wise people deploy their knowledge and skills toward the common good by balancing interests (theirs, others’, and society’s) and time horizons (short- and long-term).
Emerging consensus models integrate these perspectives, either conceptually or by surveying wisdom researchers directly. Across approaches, wisdom converges on a cluster of metacognitive skills—context sensitivity, intellectual humility, interest balancing, and perspective integration—which we term perspectival metacognition. Rooted in philosophical perspectivism, it shifts the goal of reasoning from finding a single ‘correct’ answer toward achieving a state of maximal situational clarity, attained by evaluating and coordinating competing interpretations.
Although individuals vary in these skills, most people show them to some extent, for example, when planning ahead or coordinating within social groups. This view challenges the notion that wisdom is reserved for a rare elite; instead, most humans exhibit moments of both wisdom and folly.
Not all metacognition is perspectival. Whereas some metacognitive strategies (e.g., monitoring memory and checking reasoning) optimize performance on well-structured tasks with clear accuracy criteria, perspectival metacognition specifically concerns multiple, often incommensurable, perspectives. Recruited for ill-structured, value-laden social problems, in which multiple, partly incompatible, standpoints must be coordinated rather than simply judged as right or wrong, this subset of metacognition moves beyond egocentric reasoning toward balancing interests, adapting to context, and recognizing epistemic limits when decisions affect others.
Although metacognition is central to wisdom, it does not exhaust it; most wisdom models also treat concern for others and the common good as central components. One possibility is that, in many real-world contexts, such as repeated interactions with the same partners or when one’s reputation matters to third parties, the most effective way to deal with difficult life challenges, even from a self-interested standpoint, is to prioritize the common good.
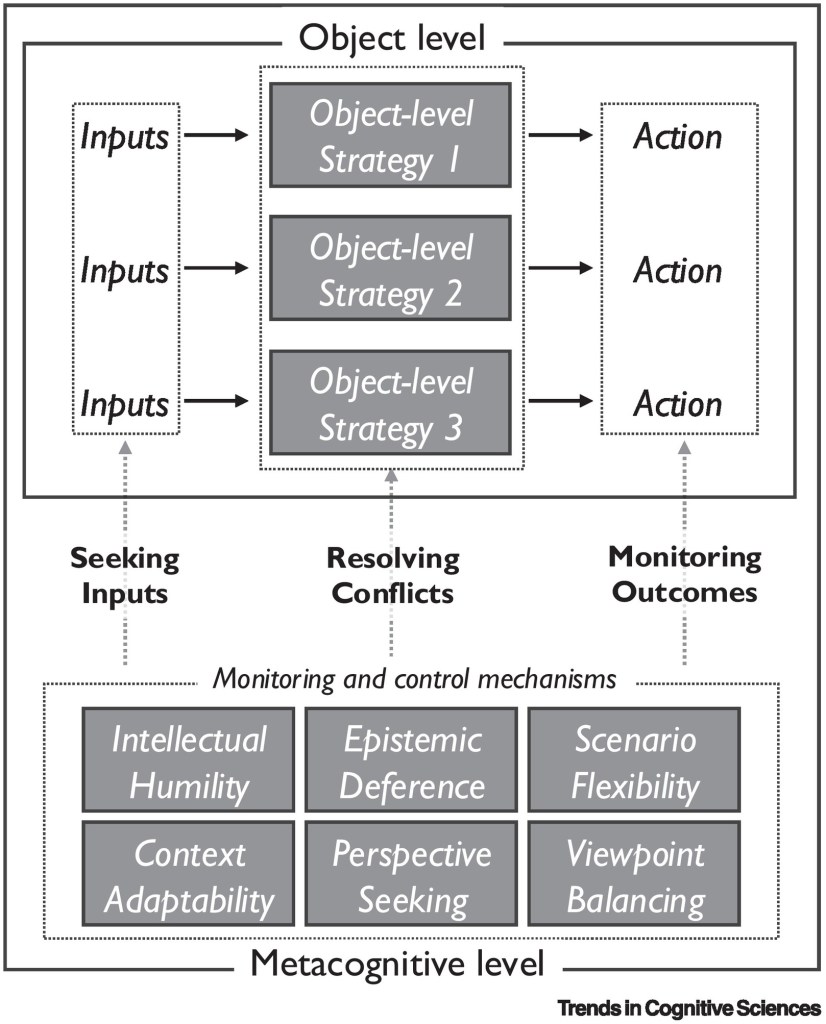
Object-level strategies (e.g., heuristics, narratives, and decision technologies) provide candidate actions for a given situation. Metacognitive monitoring and control processes regulate these strategies in three ways: obtaining the appropriate inputs, deciding which strategy to use when they conflict, and monitoring their outcomes to avoid catastrophic actions.
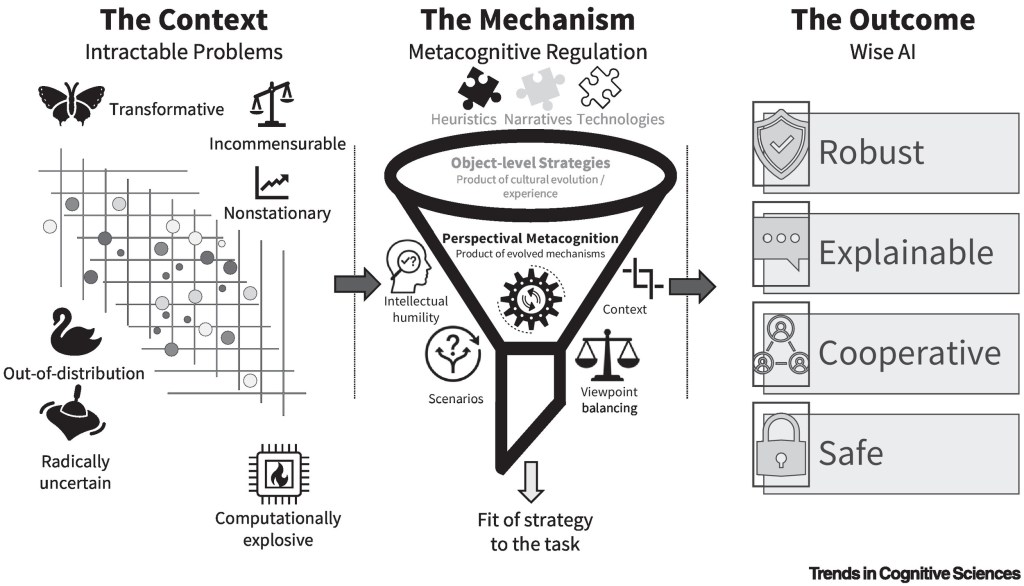
Left panel: wisdom functions specifically to solve intractable problems—situations that resist analytic optimization due to incommensurable values, radical uncertainty, or nonstationary environments.
Center panel: to address these challenges, agents deploy object-level strategies (e.g., intuitive strategies, such as heuristics and narratives, as well as technologies, such as formal procedures) derived from experience or cultural evolution. However, these strategies are often insufficient because they conflict or lack necessary inputs. Perspectival metacognition serves as the regulatory control, applying epistemic strategies (e.g., intellectual humility: awareness of what one does and does not know; acknowledgment of uncertainty and one’s fallibility) and social strategies (e.g., viewpoint balancing: recognizing and integrating discrepant interests) to select and adapt the correct object-level approach to the task at hand.
Right panel: implementing this metacognitive architecture enables AI to move beyond a narrow view of intelligence as optimization toward wisdom, resulting in systems that are more robust, explainable, cooperative, and safe.
Evaluating machine wisdom
Once we build a wise machine, how will we know it? Wisdom is context sensitive, so a benchmark input must contain sufficient detail to match the rich context of a real-world situation. Moreover, since wisdom is about the reasoning underlying strategy selection, any evaluation procedure must judge not only the outcome but also the precipitating process.
Existing benchmarking work in metacognition has focused on the calibration of confidence judgments. An advantage of this narrower domain is that it is much more tractable than the perspectival metacognitive strategies we have discussed here, with well-developed methods that even work in nonhuman animals, lend themselves to computational modeling, and are able to separate performance on the cognitive versus metacognitive components of a task. Nonetheless, these tasks are domain specific, often constrained to well-defined laboratory environments, and do not yet capture the richness of everyday intractable problems that wise judgment handles.
To make progress, let us consider how other rich, complex constructs have been benchmarked. One approach is to collect tasks from psychology experiments, akin to benchmarking theory of mind or analogical reasoning. Since these tasks are discussed in the literature (and appear in training data), the content must be replaced with structurally similar but superficially different problems. However, since these tasks usually measure outcomes only and provide little context, this approach cannot be adopted wholesale for wisdom. An alternative approach—used to benchmark explanatory abilities —is for domain experts to subjectively evaluate the quality of the model’s outputs. This approach is well suited for evaluating reasoning (rather than outcomes) but requires some form of quantification to compare models.
One way to evaluate AI wisdom would start with tasks that measure wise reasoning in humans. These tasks present participants with a social dilemma or a choice between seemingly incommensurable options and ask them to reflect on the next steps, with reflections scored on prespecified criteria by human raters, such as experts. Novel and detailed variants of such scenarios could be presented to AIs, with their performance scored by either human raters or by other models (if their scores converge). It would be important to include problems that agentic AIs might confront in the future (e.g., whether to execute a debatably ethical request) to ensure they can reason wisely not only about humans but also about themselves.
Ultimately, the wisdom of increasingly autonomous AIs will be judged by human users and stakeholders. Prior benchmarking is a crucial start, but there is no substitute for interacting with the real world. Given this intrinsic limit on our ability to evaluate wisdom ex ante, this integration with the world must proceed slowly to minimize risks.
AI wisdom would converge considerably with human wisdom.
AI wisdom also faces computational constraints, since computing can be costly. Moreover, heuristics work for AI for the same reasons as they work for humans: when we lack complete information, heuristics can perform well by implementing sensible, robust defaults. Finally, AIs may come to join our social environment—and perhaps reap some of the same social cognitive advantages as humans—as AI is increasingly integrated into human institutions.
Given these considerations, uncertainty remains.
What if we tried and failed to build wise AI?
What if the characteristics of wise AI differ from those of a wise human, to the detriment of humans? To these concerns, we have three responses.
First, if the alternative were halting all AI progress, building wise AI would introduce added risks. But compared with the status quo—advancing capabilities at a breakneck pace without wise metacognition—the attempt to make machines intellectually humble, context adaptable, and adept at balancing viewpoints seems clearly preferable.
Second, at least in the medium term, AI will not act autonomously but will remain a collaborative tool to be used by and for humans, supporting rather than replacing human wisdom. In this sense, understanding how humans and AIs might work together to produce wise or foolish decisions becomes a crucial research agenda.
Finally, the qualities of robust, explainable, cooperative, and safe AI will amplify one another. Robustness facilitates cooperation (improving confidence from counterparties) and safety (avoiding failures in novel environments). Explainability facilitates robustness (aiding human intervention through transparency) and cooperation (enabling more effective communication). Cooperation facilitates explainability (accurate theory of mind about users) and safety (implementing shared values). Wise metacognition can lead to a virtuous cycle in AI, just as it does in humans. We may not know precisely what form wise AI will take, but it must surely be preferable to folly.
