
A rather complex but very interesting article was published @PennLibraries and (somewhat more recent) @bioRXiv
But for those who want to understand by a lecture, I can recommend the Simons Faoundation lecture from Joshua Gold (also available on Youtube:
How Occam’s Razor Guides Human and Machine Decision-Making)
In this lecture, Joshua Gold describes two theoretical frameworks that support ongoing studies of deliberative decision-making in the brain, focusing on their historical origins.
The first describes quantitatively the process by which uncertain evidence can be accumulated over time to balance the competing needs of maximizing decision accuracy while minimizing decision time. This framework is built on mathematical advances that Alan Turing & colleagues developed to decode messages sent via the Enigma machine.
The second describes how biases can emerge in this information-accumulation process that can be helpful when considering options that differ in form and scope. This framework is a formalization of Occam’s razor, which states that all else being equal, simple solutions are better — an idea directly relevant to how biological and artificial brains can make effective decisions.
Occam’s razor is the principle stating that, all else being equal, simpler explanations for a set of observations are preferred over more complex ones.
This idea is central to multiple formal theories of statistical model selection and is posited to play a role in human perception and decision-making, but a general, quantitative account of the specific nature and impact of complexity on human decision-making is still missing.
Results imply that principled notions of statistical model complexity have direct, quantitative relevance to human and machine decision-making and establish a new understanding of the computational foundations, and behavioral benefits, of our predilection for inferring simplicity in the latent properties of our complex world.
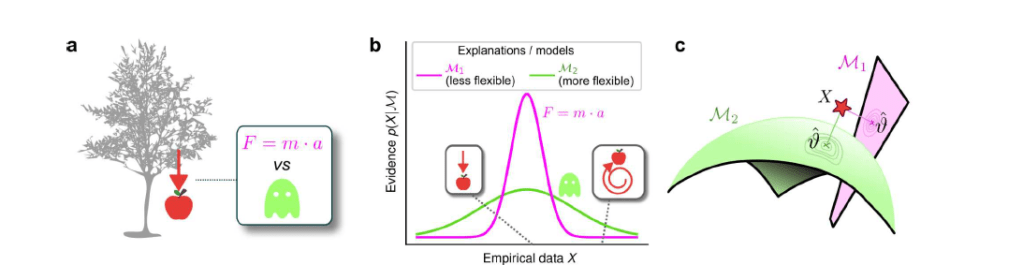
understand simplicity preferences in human decision-making.
a: Occam’s razor prescribes an aversion to complex explanations (models). In Bayesian model selection, model complexity is a measure of the flexibility of a model, or its capacity to account for a broad range of empirical observations. In this example, we observe an apple falling from a tree (left) and compare two possible explanations: 1) classical mechanics, and 2) the intervention of a ghost.
b: Schematic comparison of the evidence of the two models in a. Classical mechanics (pink) explains a narrower range of observations than the ghost (green), which is a valid explanation for essentially any conceivable phenomenon (e.g., both a falling and spinning-upward trajectory, as in the insets). Absent further evidence, Occam’s razor posits that the simpler model (classical mechanics) is preferred, because its hypothesis space is more concentrated around the sparse, noisy data and thus avoids “overfitting” to noise.
c: A geometrical view of the model-selection problem. Two alternative models are represented as geometrical manifolds, and the maximum-likelihood point ϑ for each model is represented as the projection of the data (red star) onto the manifolds.
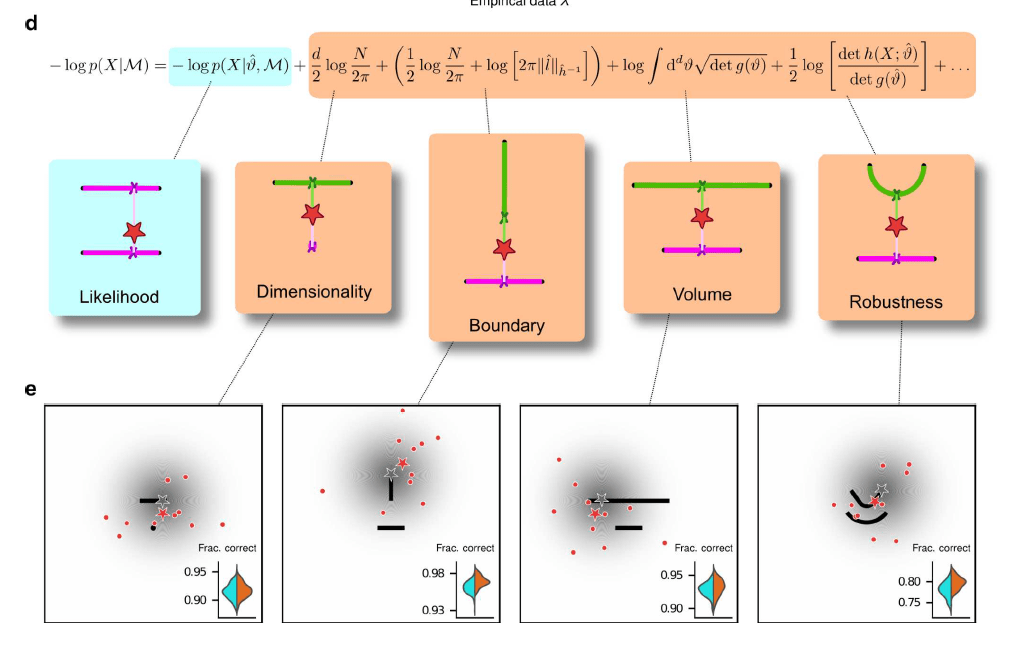
e: Psychophysical task with variants designed to probe each geometrical feature in d. For each trial, a random location on one model was selected (gray star), and data (red dots) were sampled from a Gaussian centered around that point (gray shading). The red star represents the empirical centroid of the data, by analogy with c. The maximum-likelihood point can be found by projecting the empirical centroid onto one of the models. Subjects saw the models (black lines) and data (red dots) only and were required to choose which model was best for the data. Insets: task performance for the given task variant, for a set of 100 simulated ideal Bayesian observers (orange) versus a set of 100 simulated maximum-likelihood observers (i.e., choosing based only on whichever model was the closest to the empirical centroid of the data on a given trial; cyan).
Simplicity has long been regarded as a key element of effective reasoning and rational decision-making, and it has been proposed as a foundational principle in philosophy, psychology, statistical inference, and more recently machine learning.
Accordingly, multiple studies have identified preferences for simplicity in human
cognition, such as a tendency to prefer smoother (simpler) curves as the inferred, latent source of noisy observed data. However, the quantitative form and magnitude of this preference have never been identified. In this work, we showed that the simplicity preference is closely related to a specific mathematical formulation of Occam’s razor, situated at the convergence of Bayesian model selection and information theory. This formulation enabled us to go beyond the mere detection of a preference for simple explanations for data and to measure precisely the strength of this preference in artificial and human subjects under a variety of theoretically motivated conditions.
This study makes several novel contributions.
The first is theoretical: we derived a new term of the Fisher Information Approximation (FIA) in Bayesian model selection that accounts for the possibility that the best model is on the boundary of the model family. This boundary term is important because it can account for the possibility that, because of the noise in the data, the best value of one parameter (or of a combination of parameters) takes on an extreme value. This condition is related to the phenomenon of “parameter evaporation” that is common in real-world models for data. Moreover, boundaries for parameters are particularly important for studies of perceptual decision-making, in which sensory stimuli are limited by the physical constraints of the experimental setup and thus reasoning about unbounded parameters would be problematic for subjects. For example, imagine designing an experiment that requires subjects to report the location of a visual stimulus. In this case, an unbounded set of possible locations (e.g., along a line that stretches infinitely far in the distance to the left and to the right) is clearly untenable. Our “boundary” term formalizes the impact of considering the set of possibilities as having boundaries, which tend to increase local complexity because they tend to reduce the number of local hypotheses close to the data (see Figure b).
The second contribution of this work relates to ANNs: these networks can learn to use or ignore the simplicity preferences in an optimal way (i.e., according to the magnitudes prescribed by the theory), depending on how they are trained. These results are different from, and complementary to, recent work that has focused on the idea that implementation of simple functions could be key to generalization in deep neural networks. Here we have shown that effective learning can take into account the complexity of the hypothesis space, rather than that of the decision function, in producing normative simplicity preferences. On the one hand, these results do not seem surprising, because ANNs, and deep networks in particular, are powerful function approximators that perform well in practice on a vast range of inference tasks. Accordingly, our ANNs trained with respect to the true generative solutions were able to make effective decisions, including simplicity preferences, about the generative source of a given set of observations. Likewise, our ANNs trained with respect to maximum-likelihood solutions were able to make effective decisions, without simplicity preferences, about the maximum-likelihood match for a given set of observations. On the other hand, these results provide new insights into how ANNs might be analyzed to better understand the kinds of solutions they produce for particular problems. In particular, assessing the presence or absence of these kinds of simplicity preferences might help identify if and/or how well an ANN is likely to avoid overfitting to training data and provide more generalizable solutions.
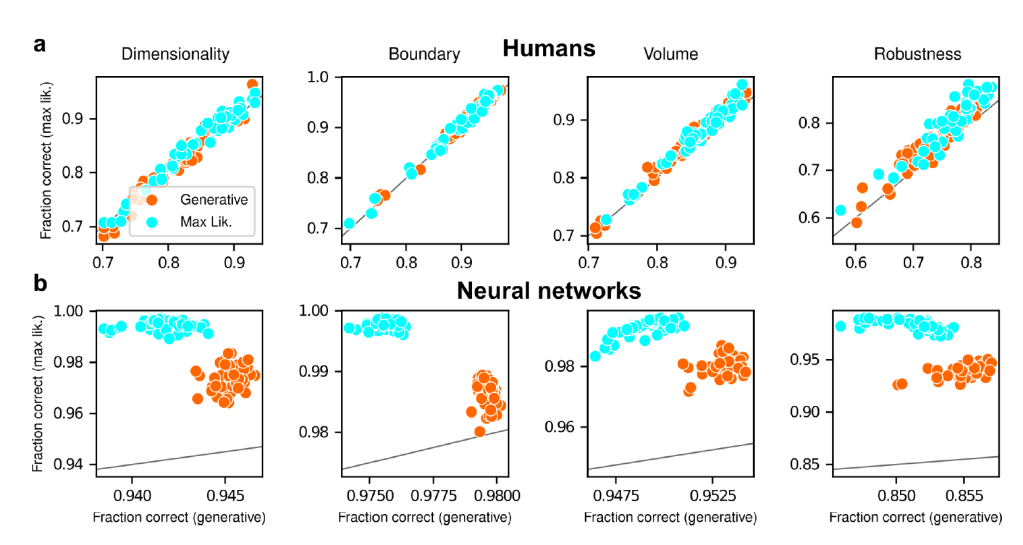
reflecting their different use of simplicity preferences
Each panel shows accuracy with respect to maximum-likelihood solutions (i.e., the model closest to the centroid of the data; ordinate) versus with respect to generative solutions (i.e., the model that generated the data; abscissa). The gray line is the identity. Columns correspond to the four task variants associated with the four geometric complexity terms.
a: Data from individual human subjects (points), instructed to find the generative (orange) or maximum-likelihood (cyan) solution. Subject performance was higher when evaluated against maximum-likelihood solutions than it was when evaluated against generative solutions, for all groups of subjects.
b: Data from individual ANNs (points), trained on the generative (orange) or maximum-likelihood (cyan) task. Network performance was always highest when evaluated against maximum-likelihood solutions, compared to generative solutions (all dots are above the identity line).
The third, and most important, contribution of this work relates to human behavior: people tend to use simplicity preferences when making decisions, and unlike ANNs these preferences do not seem to be simply the consequences of learning specific task demands but rather an inherent part of how we interpret uncertain information. This tendency has important implications for the kinds of computations our brains must use to solve these kinds of tasks, and how those computations appear to differ from those implemented by the ANNs we used. From a theoretical perspective, the difference between a Bayesian solution (i.e., one that includes the simplicity preferences) and a maximum-likelihood solution (i.e., one that does not include the simplicity preferences) to these tasks is that the latter considers only the single best-fitting model from each family, whereas the former integrates over all possible models in each family.
Our finding that ANNs can converge on either solution when trained appropriately indicates that both are, in principle, learnable. However, our finding that people tend to use the Bayesian solution even when instructed to use the maximum-likelihood solution suggests that we naturally do not make decisions based simply on the single best or archetypical instance within a family of possibilities but rather integrate across that family.
Put more concretely in terms of our task, when told to identify the shape closest to the data points, subjects were likely uncertain about which exact location on each shape was closest and thus integrated over the possibilities – thus inducing simplicity preferences as prescribed by the Bayesian solution.
Another key feature of our findings that merits further study is the magnitude and variability of preferences exhibited by the human subjects.
On average, human sensitivity to each geometrical model feature was:
1) larger than zero,
2) at least slightly different from the optimal value (e.g., larger for dimensionality and robustness, smaller for volume),
3) different for distinct features and different subjects; and
4) independent of instructions and training.
People may weigh more heavily the model features that are easier or cheaper to compute. In our experiments, the most heavily weighted feature was model dimensionality. In our mathematical framework, this feature corresponds to the number of degrees of freedom of a possible explanation for the observed data and thus can be relatively easy to assess. By contrast, the least heavily weighted feature was model volume. This feature involves integrating over the whole model family (to count how many distinct states of the world can be explained by a certain hypothesis, one needs to enumerate them) and thus can be very difficult to compute. The other two terms, boundary and robustness, are intermediate in terms of human weighting and computational difficulty: they are harder to compute than dimensionality, because they depend on the data and on the properties of the model at the maximum likelihood location, but are also simpler than the volume term, because they are local quantities that do not require integration over the whole model manifold.
