
“Robust Decision-Making Via Free Energy Minimization” html, pdf, video, Nature Communications
Despite their groundbreaking performance, state-of-the-art autonomous agents can misbehave when training and environmental conditions become inconsistent, with minor mismatches leading to undesirable behaviors or even catastrophic failures. Robustness towards these training/environment ambiguities is a core requirement for intelligent agents and its fulfillment is a long-standing challenge when deploying agents in the real world. Here, departing from mainstream views seeking robustness through training, we introduce DR-FREE, a free energy model that installs this core property by design.
It directly wires robustness into the agent decision-making mechanisms via free energy minimization. By combining a robust extension of the free energy principle with a novel resolution engine, DR-FREE returns a policy that is optimal-yet-robust against ambiguity. Moreover, for the first time, it reveals the mechanistic role of ambiguity on optimal decisions and requisite Bayesian belief updating. We evaluate DR-FREE on an experimental testbed involving real rovers navigating an ambiguous environment filled with obstacles. Across all the experiments, DR-FREE enables robots to successfully navigate towards their goal even when, in contrast, standard free energy minimizing agents that do not use DR-FREE fail.
In short, DR-FREE can tackle scenarios that elude previous methods: this milestone may inspire both deployment in multi-agent settings and, at a perhaps deeper level, the quest for a biologically plausible explanation of how natural agents – with little or no training – survive in capricious environments.
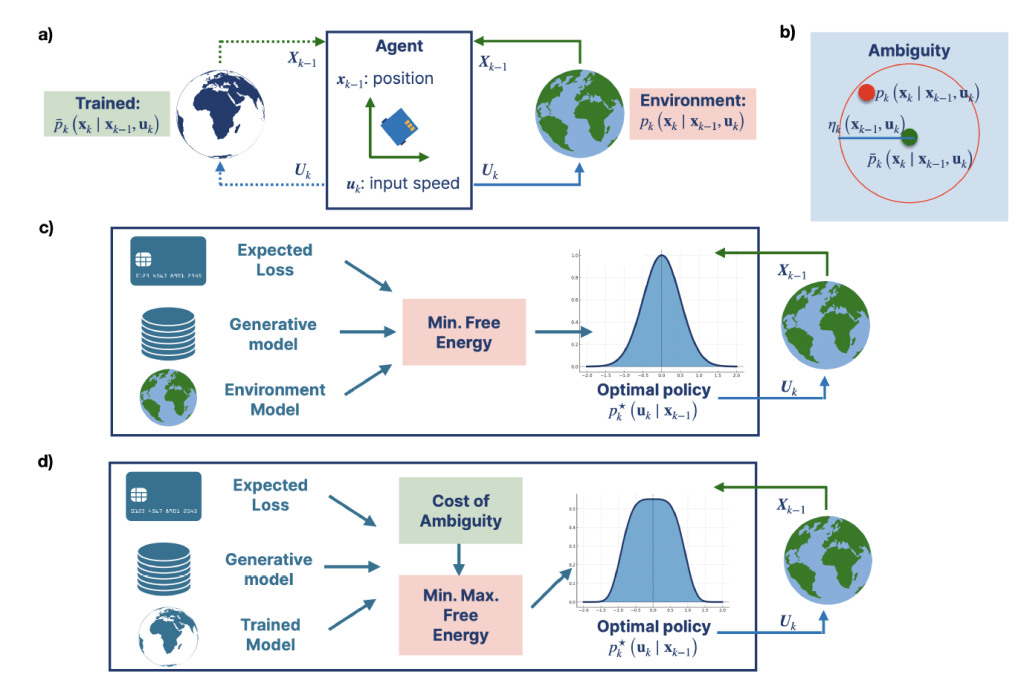
a. A robotic agent navigating a stochastic environment to reach a destination while avoiding obstacles. At a given time-step, k − 1, the agent determines an action Uk from a policy using a model of the environment (e.g., available at training via a simulator possibly updated via real world data) and observations/beliefs (grouped in the state Xk−1). The environment and model can change over time. Capital letters are random variables, lower-case letters are realizations.
b. The trained model and the agent environment differ. This mismatch is a training/environment ambiguity: for a state/action pair, the ambiguity set is the set of all possible environments that have statistical complexity from the trained model of at most ηk (xk−1,uk). We use the wording trained model in a very broad sense. A trained model is any model available to the agent offline: for example, this could be a model obtained from a simulator or, for natural agents, this could be
hardwired into evolutionary processes or even determined by prior beliefs.
c. A free energy minimizing agent in an environment matching its own model. The agent determines an action by sampling from the policy p⋆k (uk ∣ xk−1). Given the model, the policy is obtained by minimizing the variational free energy: the sum of a statistical complexity (with respect to a generative model) and expected loss terms.
d. DR-FREE extends the free energy principle to account for model ambiguities. According to DR-FREE, the maximum free energy across all environments – in an ambiguity set – is minimized to identify a robust policy. This amounts to variational policy optimization under the epistemic uncertainty engendered by ambiguous environmnent.
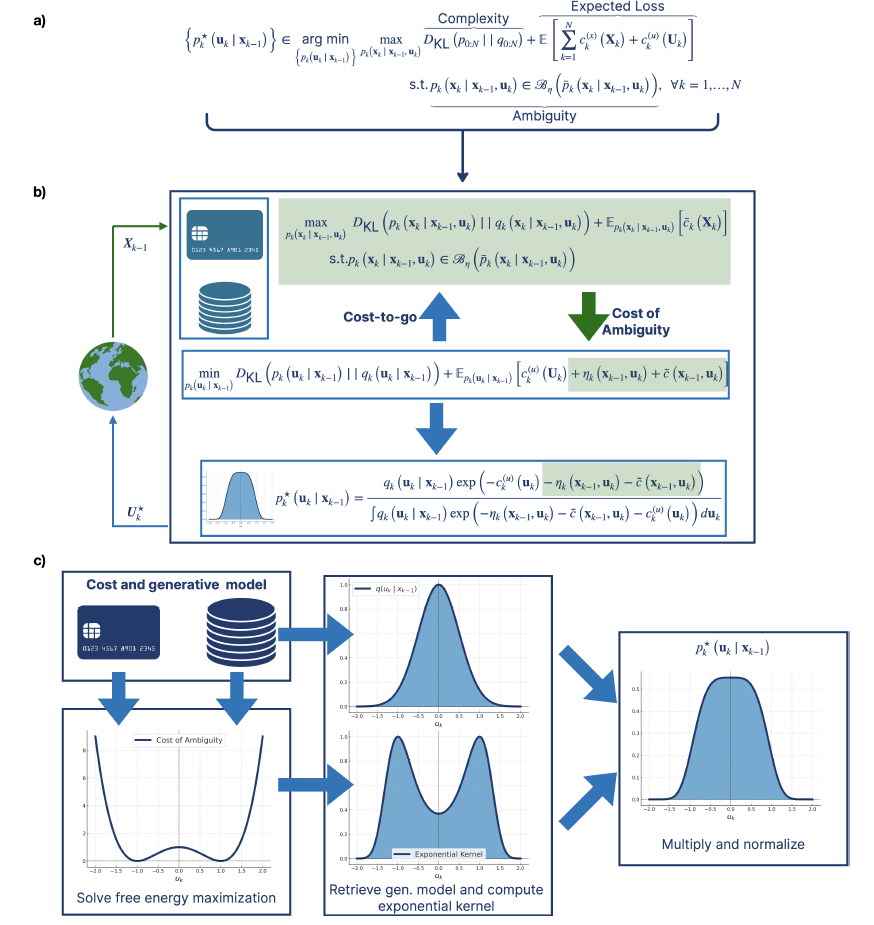
a. Summarizing the distributionally robust free energy minimization principle. Our generalization of active inference yields an optimization framework where policies emerge by minimizing the maximum free energy (comprising complexity and expected loss) over all possible environments in the ambiguity set.
b. The resolution engine to find the policy. Given the current state, the engine uses the generative model and the loss to find the maximum free energy DKL
c. Using the generative model and the state-cost, DR-FREE first computes the cost of ambiguity, which is non-negative. This, together with the action cost is then used to obtain the exponential kernel in the optimal policy.
Robustness is a core requirement for intelligent agents that need to operate in the real world.
Rather than leaving its fulfillment to an emergent and potentially brittle property from training, DR-FREE ensures this core requirement by design, building on the minimization of the free energy and installing sequential policy optimization into a rigorous (variational or Bayesian) framework. DR-FREE provides, for the first time, not only a free energy minimization principle that accounts for environmental ambiguity, but also the resolution engine to address the resulting sequential policy optimization framework. This milestone, important because addresses a grand challenge for intelligent machines operating in open-worlds, tackles settings that are simply out of reach for previous excellent methods. Moreover, in doing so, DR-FREE elucidates the mechanistic role of ambiguity on optimal decisions and its policy supports (Bayesian) belief-based updates.
Finally, DR-FREE establishes what are the limits of performance in the face of ambiguity, showing that, at a very fundamental level, it is impossible for an agent affected by ambiguity to outperform an ambiguity-free free energy minimizing agent. These analytic results are confirmed by our experiments.
If, quoting the popular aphorism, all models are wrong, but some are useful, then relaxing the requirements on training, DR-FREE makes more models useful. This is achieved by departing from views that emphasize the role, and the importance, of training: in DR-FREE the emphasis is instead on rigorously installing robustness into decision-making mechanisms.
With its robust free energy minimization principle and resolution engine, DR-FREE suggests that, following this path, intelligent machines can recover robust policies from largely imperfect, or even poor, models.
We hope that this work may inspire both the deployment of our free energy model in multi-agent settings (with heterogeneous agents such as drones, autonomous vessels and humans) across a broad range of application domains and, combining DR-FREE with Deep RL, lead to novel learning schemes that – learning ambiguity – succeed when classic methods fail.
At a perhaps deeper level, this work may provide the foundation for a biologically plausible neural explanation of how natural agents – with little or no training – can operate robustly in challenging environments.
