
Sohna and Jazayeri discuss in “Validating model-based Bayesian integration using prior–cost metamers” the two competing views on how humans make decisions under uncertainty. Bayesian decision theory (BDT) posits that humans optimize their behavior by establishing and integrating internal models of past sensory experiences (priors) and decision outcomes (cost functions). An alternative hypothesis posits that decisions are optimized through trial and error without explicit internal models for priors and cost functions.
To distinguish between these possibilities, they introduce a paradigm that probes the sensitivity of humans to transitions between prior–cost pairs that demand the same optimal policy (metamers) but distinct internal models. The research demonstrates the utility of the approach in two experiments that were classically explained by Bayesian theory. Our approach validates the Bayesian learning strategy in an interval timing task but not in a visuomotor rotation task. More generally, this work provides a domain-general approach for testing the circumstances under which humans explicitly implement model-based Bayesian computations.
Over the last decade, Bayesian modeling has emerged as a unified approach for capturing a wide range of behaviors such as perceptual illusions, cognitive decision making, and motor control. Despite its remarkable success, the Bayesian approach has been challenged by the issue of model identifiability; that is, the components of a Bayesian model (e.g., prior and cost function) are not uniquely determined by the behavior. Here, we create an experimental paradigm that provides a way to adjudicate whether and when humans build and use the internal models of priors and cost functions. This research work provides a path toward resolving the controversies surrounding the notion of the Bayesian brain.
(A) Ideal-observer model. An agent generates an optimal estimate (e) of stimulus (s) based on a noisy measurement (m). To do so, the agent must compute the optimal decision policy (rectangular box; e = f(m)) that maximizes expected reward. The decision policy can be computed using either an implicit (Top) or explicit (Bottom) learning strategy. In implicit learning, the policy is optimized through trial and error (e.g., model-free reinforcement learning) based on measurements and decision outcomes (arrows on top). In explicit learning, the agent derives the optimal policy by forming internal models for the stimulus prior probability, p(s), the likelihood of the stimulus after measurement, p(m|s), and the underlying cost function, c(e,s).
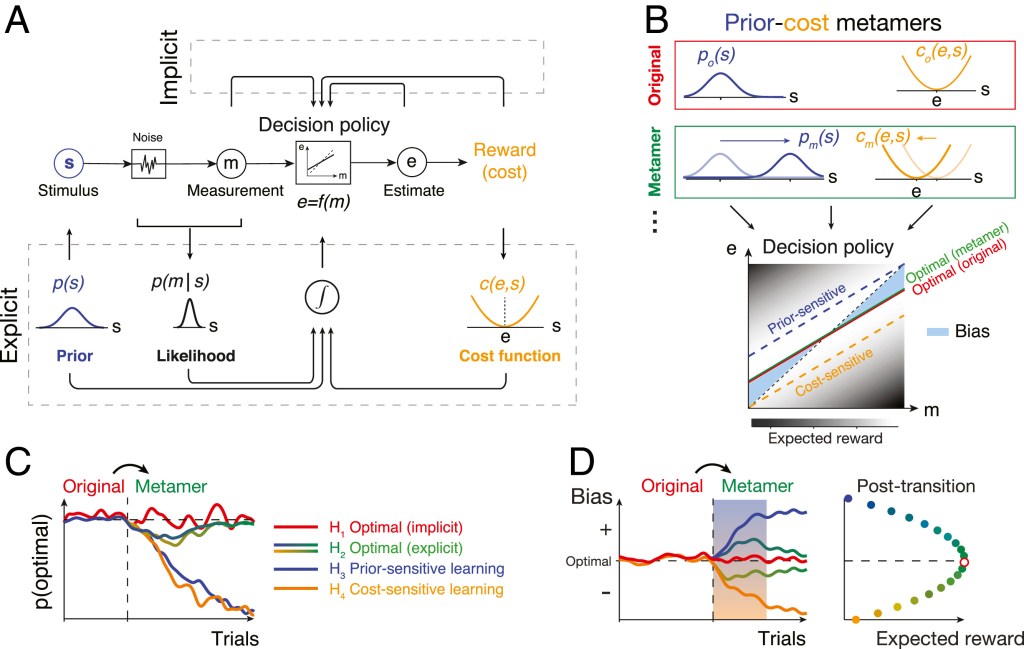
(B) Prior–cost metamers are different p(s) and c(e,s) pairs that lead to the same decision policy. Red box: an original pair (subscript o) showing a Gaussian prior, po(s), and a quadratic cost function, co(e,s). Green box: a metameric pair (subscript m) whose Gaussian prior, pm(s), and quadratic cost function, cm(e,s), are suitably shifted to the right and left, respectively. (Bottom) The optimal decision policy (e = f(m)) associated with both the original (red) and metamer (green) conditions is shown as a line whose slope is less than the unity line (black dashed line; unbiased). The colored dashed lines show suboptimal policies associated with an agent that is only sensitive to the change in prior (blue) or only sensitive to the change in the cost function (orange). The policy is overlaid on a gray scale map that shows expected reward for various mappings of m to e.
(C) Simulation of different learning models that undergo an uncued transition (vertical dashed line) from the original pair to its metamer. H1 (implicit): after the transition, the agent continues to use the optimal policy associated with the original condition. Since this is also the optimal policy for the metamer, probability of behavior being optimal, p(optimal), does not change. H2 (explicit): immediately after the transition, the agent has to update its internal model for the new prior and cost function. This relearning phase causes a transient deviation from the optimality (blue-to-green and yellow-to-green lines after the switch). After learning, the behavior becomes optimal since the optimal policy for the metamer is the same as the original. H3 (prior sensitive): the agent only learns the new prior, which leads to a suboptimal behavior. H4 (cost sensitive): same as H3 for an agent that only learns the new cost function.
(D) Same as C for the response biases as a behavioral metric. Similar to p(optimal) in C, bias of the implicit model (H1) remains at the optimal level and expected reward remains at the maximum level (Right). The explicit model (H2) shows transient deviation from the optimal bias (blue-to-green and yellow-to-green lines) and expected reward decreases (Right). Prior-sensitive and cost-sensitive models have opposite signs of biases and larger decrease in expected reward (Right).
The success of the BDT in capturing human decision making under uncertainty has been taken as evidence that the human brain relies on internal models for prior probability, sensory likelihoods, and reward contingencies.
Our analysis of learning dynamics […] suggests that updating priors and cost functions likely involves different neural systems. This conclusion is consistent with the underlying neurobiology.
Humans and animals update their prior beliefs when observed stimuli deviate from predictions, which can be quantified in terms of the sensory prediction error (SPE). The cerebellum is thought to play a particularly important role in supervised SPE-dependent learning of stimulus statistics in sensorimotor behaviors.
In contrast, learning cost functions is thought to depend on computing reward prediction error (RPE) between actual and expected reward. This type of learning is thought to involve the midbrain dopaminergic system in conjunction with the cortico-basal ganglia circuits.
Finally, the information about the prior and cost function has to be integrated to drive optimal behavior.
Currently, the neural circuits and mechanisms that are responsible for this integration are not well understood. Future work could take advantage of our methodology to systematically probe behavioral settings that rely on model-based BDT as a rational starting point for making inquiries about the underlying neural mechanisms.
